构建多智能体AI🤖👱🏼🤖-第三章-LangGraph构建多智能体工作流
上⼀章节我在没有⼤模型的加持下,全⾯演练了LangGraph的Graph图结构。 这⼀章节,就结合⼤模型,来深⼊理解LangGraph如何通过Graph构建复杂的⼤模型应⽤。
一、流式输出大模型调用结果
在介绍Graph的流式输出时,我提到LangGraph的Graph流式输出有⼏种不同的模式,其中有⼀种messages模式,是⽤来监控⼤语⾔模型的Token记录的。这⾥就可以来测试⼀下。
from langchain_community.chat_models import ChatTongyi # 导入阿里云百炼大模型的接口
from langgraph.graph import StateGraph, MessagesState, START # 导入状态图构建器和消息状态
from langgraph.checkpoint.memory import InMemorySaver # 导入内存保存器
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus", # 使用的模型名称
api_key="key", # 加载 API 密钥
)
# 定义节点处理函数
def call_model(state: MessagesState):
# 使用 ChatTongyi 的 invoke 方法调用大模型,并传入消息
response = llm.invoke(state["messages"])
return {"messages": response} # 返回模型生成的消息
# 创建状态图
builder = StateGraph(MessagesState)
# 添加节点到状态图,节点执行 call_model 函数
builder.add_node(call_model)
# 添加边,连接 START 节点到 call_model 节点
builder.add_edge(START, "call_model")
# 编译状态图
graph = builder.compile()
# 执行图的流式处理
# 传入初始状态,包含用户提问 "湖南的省会是哪儿?"
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "广西的省会是哪儿?"}]},
stream_mode="messages", # 流模式为 "messages",表示按消息流处理
):
print(chunk) # 打印每个流处理的结果通常,如果要对⼤模型调⽤成本进⾏统计时,这种messages就是比较好的⼀种⽅式。
二、大模型消息持久化
和之前介绍LangGraph的Agent相似,Graph图也⽀持构建消息的持久化功能。并且也通常⽀持通过checkpointer构建短期记忆,以store构建⻓期记忆。
这⾥短期记忆和⻓期记忆,都是可以通过内存或者数据库进⾏持久化保存的。不过短期记忆更倾向于通过对消息的短期存储,实现多轮对话的效果。而⻓期记忆则倾向于对消息⻓期存储后⽀持语义检索。
from langchain_community.chat_models import ChatTongyi # 导入阿里云百炼大模型接口
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus", # 使用的模型名称
api_key="key", # 加载 API 密钥
)
from langgraph.graph import StateGraph, MessagesState, START # 导入状态图构建器和消息状态
from langgraph.checkpoint.memory import InMemorySaver # 导入内存保存器
# 定义节点的处理逻辑
def call_model(state: MessagesState):
# 使用 ChatTongyi 客户端的 invoke 方法调用大模型,传入消息并获得响应
response = llm.invoke(state["messages"])
return {"messages": response} # 返回包含模型响应的消息
# 创建状态图,状态类型为 MessagesState
builder = StateGraph(MessagesState)
# 向状态图添加节点,节点执行 call_model 函数
builder.add_node(call_model)
# 定义从 START 到 "call_model" 的边
builder.add_edge(START, "call_model")
# 创建内存保存器(检查点),用于保存节点状态
checkpointer = InMemorySaver()
# 编译图并应用检查点
graph = builder.compile(checkpointer=checkpointer)
# 配置设置
config = {
"configurable": {
"thread_id": "1" # 可配置的线程 ID
}
}
# 执行图的流式处理
# 第一次查询:湖南省的省会
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "湖南的省会是哪儿?"}]},
config,
stream_mode="values", # 流模式为 "values",表示按值传输
):
chunk["messages"][-1].pretty_print() # 打印模型生成的消息
# 第二次查询:湖北省的省会
for chunk in graph.stream(
{"messages": [{"role": "user", "content": "湖北呢?"}]},
config,
stream_mode="values", # 流模式为 "values"
):
chunk["messages"][-1].pretty_print() # 打印模型生成的消息三、Human-In-Loop⼈类⼲预
在LangGraph中也可以通过中断任务,等待确认的⽅式,来实现过程⼲预,这样能够更好的减少⼤语⾔模型的结果不稳定给任务带来的影响。
在具体实现⼈类⼲预时,需要注意⼀下⼏点:
必须指定⼀个checkpointer短期记忆,否则⽆法保存任务状态
在执⾏Graph任务时,必须指定⼀个带有thread_id的配置项,指定线程ID。之后才能通过线程ID,指定恢复线程。
在任务执⾏过程中,通过interrupt()⽅法,中断任务,等待确认。
在⼈类确认之后,使⽤Graph提交⼀个resume=True的Command指令,恢复任务,并继续进⾏。
这种实现⽅式,在之前介绍LangGraph构建单Agent时已经介绍过,不过,结合Graph的State,在多个Node之间进⾏复杂控制,这样更能体现出⼈类监督的价值。
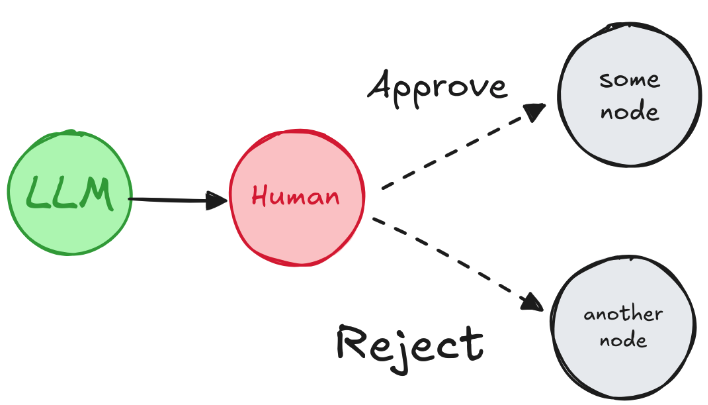
例如,下⾯的案例可以实现这样⼀种典型的⼈类确认:
from operator import add
from langchain_core.messages import AnyMessage
from langgraph.checkpoint.memory import InMemorySaver # 内存保存器,用于保存节点状态
from langgraph.constants import START, END # 图的起始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
from langchain_community.chat_models import ChatTongyi # 导入阿里云百炼大模型接口
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus", # 使用的模型名称
api_key="key", # 加载 API 密钥
)
from typing import Literal, TypedDict, Annotated
from langgraph.types import interrupt, Command # 导入用于中断和控制流的工具
# 配置状态类型 State,表示图的状态
class State(TypedDict):
messages: Annotated[list[AnyMessage], add] # 消息列表,存储传递给模型的消息
# 定义人工审批节点
# 该节点会询问用户是否同意调用大语言模型
def human_approval(state: State) -> Command[Literal["call_llm", END]]:
# 提问用户是否同意调用大语言模型
is_approved = interrupt(
{
"question": "是否同意调用大语言模型?"
}
)
# 根据用户的回答,返回相应的命令
if is_approved:
return Command(goto="call_llm") # 同意调用大语言模型,跳转到 call_llm 节点
else:
return Command(goto=END) # 拒绝调用,跳转到 END 节点
# 定义调用大语言模型的节点
def call_llm(state: State):
# 调用大语言模型,并获取模型响应
response = llm.invoke(state["messages"])
return {"messages": [response]} # 返回模型生成的消息
# 创建状态图,状态类型为 State
builder = StateGraph(State)
# 向图中添加节点
builder.add_node("human_approval", human_approval) # 添加人工审批节点
builder.add_node("call_llm", call_llm) # 添加调用大语言模型节点
# 添加从 START 到 "human_approval" 节点的边
builder.add_edge(START, "human_approval")
# 创建内存保存器,保存节点的状态
checkpointer = InMemorySaver()
# 编译图,生成可执行的图对象
graph = builder.compile(checkpointer=checkpointer)from langchain_core.messages import HumanMessage
# 提交任务,等待确认
thread_config = {"configurable": {"thread_id": 1}}
graph.invoke({"messages": [HumanMessage("湖南的省会是哪⾥?")]}, config=thread_config)
# 执⾏后会中断任务,等待确认# 确认同意,继续执⾏任务
final_result = graph.invoke(Command(resume=True), config=thread_config)
print(final_result)
# 不同意,终⽌任务
# final_result = graph.invoke(Command(resume=False), config=thread_config)
# print(final_result)注意:
任务中断和恢复,需要保持相同的thread_id。通常应⽤当中都会单独⽣成⼀个随机的thread_id,保证唯⼀的同时,防⽌其他任务⼲扰。
interrupt()⽅法中断任务的时间不能过⻓,过⻓了之后就⽆法恢复任务了。
任务确认时,Command中传递的resume可以是简单的True或False,也可以是⼀个字典。通过字典可以进⾏更多的判断。
四、Time Travel时间回溯
由于⼤语⾔模型回答问题的不确定性,基于⼤语⾔模型构建的应⽤,也是充满不确定性的。⽽对于这种不确定性的系统,就有必要进⾏更精确的检查。当某⼀个步骤出现问题时,才能及时发现问题,并从发现问题的那个步骤进⾏重演。为此,LangGraph提供了Time Travel时间回溯功能,可以保存Graph的运⾏过程,并可以⼿动指定从Graph的某⼀个Node开始进⾏重演。
具体实现时,需要注意以下⼏点:
在运⾏Graph时,需要提供初始的输⼊消息。
运⾏时,指定thread_id线程ID。并且要基于这个线程ID,再指定⼀个checkpoint检查点。执⾏后将在每⼀个Node执⾏后,⽣成⼀个check_point_id
指定thread_id和check_point_id,进⾏任务重演。重演前,可以选择更新state,当然,如果没问题,也可以不指定。
from typing import TypedDict
from typing_extensions import NotRequired
from langgraph.checkpoint.memory import InMemorySaver # 导入内存保存器
from langgraph.constants import START, END # 导入图的起始和结束常量
from langgraph.graph import StateGraph # 导入状态图构建器
from langchain_community.chat_models import ChatTongyi # 导入阿里云百炼大模型接口
# 构建阿里云百炼大模型客户端
llm = ChatTongyi(
model="qwen-plus", # 使用的模型名称
api_key="key", # 加载 API 密钥
)
# 定义图的状态结构,包含两个字段:作者和笑话
class State(TypedDict):
author: NotRequired[str] # 可选的作者字段
joke: NotRequired[str] # 可选的笑话字段
# 定义推荐作者的节点
def author_node(state: State):
# 请求模型推荐一位受人欢迎的作家
prompt = "帮我推荐一位受人们欢迎的作家。只需要给出作家的名字即可。"
author = llm.invoke(prompt) # 调用大模型生成推荐的作家
return {"author": author} # 返回推荐的作家
# 定义写笑话的节点
def joke_node(state: State):
# 请求模型用推荐的作家的风格写一个笑话
prompt = f"用作家:{state['author']} 的风格,写一个100字以内的笑话"
joke = llm.invoke(prompt) # 调用大模型生成笑话
return {"joke": joke} # 返回生成的笑话
# 创建状态图,状态类型为 State
builder = StateGraph(State)
# 添加节点到状态图
builder.add_node(author_node) # 添加推荐作家的节点
builder.add_node(joke_node) # 添加写笑话的节点
# 添加从 START 到 "author_node" 的边
builder.add_edge(START, "author_node")
# 添加从 "author_node" 到 "joke_node" 的边
builder.add_edge("author_node", "joke_node")
# 添加从 "joke_node" 到 END 的边
builder.add_edge("joke_node", END)
# 创建内存保存器,用于保存节点的状态
checkpointer = InMemorySaver()
# 编译图,生成可执行的图对象
graph = builder.compile(checkpointer=checkpointer)
# 输出编译后的图对象
graph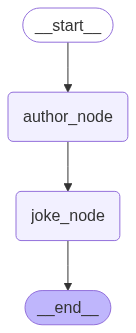
import uuid # 导入 uuid 模块,用于生成唯一标识符
# 配置设置,包含一个动态生成的唯一的 thread_id
config = {
"configurable": {
"thread_id": uuid.uuid4(), # 使用 uuid 生成一个唯一的线程 ID
}
}
# 执行图,传入初始状态和配置
state = graph.invoke({}, config) # 调用图并传递初始状态和配置
# 打印生成的状态中的 "author" 和 "joke" 字段
print(state["author"]) # 打印推荐的作家
print()
print(state["joke"]) # 打印根据作家风格生成的笑话# 查看所有checkpoint检查点
states = list(graph.get_state_history(config))
for state in states:
print(state.next)
print(state.config["configurable"]["checkpoint_id"])
print()# 选定某⼀个检查点。这⾥选择author_node,让⼤模型重新推荐作家
selected_state = states[1]
print(selected_state.next)
print(selected_state.values)# 为了后⾯的重演,更新state。可选步骤:
new_config = graph.update_state(selected_state.config, values={"author": "郭德纲"})
print(new_config)# 接下来,指定thread_id和checkpoint_id,进⾏重演
graph.invoke(None,new_config)得到结果:
{'author': '郭德纲',
'joke': AIMessage(content='今儿个说一事儿,我跟于谦老师去饭店吃饭,点俩菜,一拍黄瓜,一盘木耳。服务员问我要什么饮料,我说来瓶啤酒。您猜怎么着?那服务员愣是给我上了一瓶墨汁!我说这谁调的酒啊,服务员说:“先生,这叫黑啤!”哎呦喂,这年头,喝个酒都能喝出文化来!', additional_kwargs={}, response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'stop', 'request_id': '27f18b1f-ee88-9947-bece-b09be2ed85cb', 'token_usage': {'input_tokens': 30, 'output_tokens': 90, 'total_tokens': 120, 'prompt_tokens_details': {'cached_tokens': 0}}}, id='run--935850b2-d1eb-4487-934b-00a9f7e81120-0')}五、多智能体架构
可以看到,在LangChain体系中,LangChain主要集成了和⼤语⾔模型交互的能⼒,⽽LangGraph主要实现了复杂的流程调度。将这两个能⼒结合起来,⼀个强⼤的多智能体构建框架就已经成型了。
接下来,我们就⽤LangGraph来实现⼀个⾮常典型的多智能体架构,作为⼀个完整的案例。
这个机器⼈可以通过⼀个supervisor节点,对⽤户的输⼊进⾏分类,然后根据分类结果,选择不同的agent节点进⾏处理。
接下来每个Agent节点,都可以选择不同的⼯具进⾏处理,最后将处理结果汇总,返回给supervisor节点。
supervisor节点再将结果返回给⽤户。
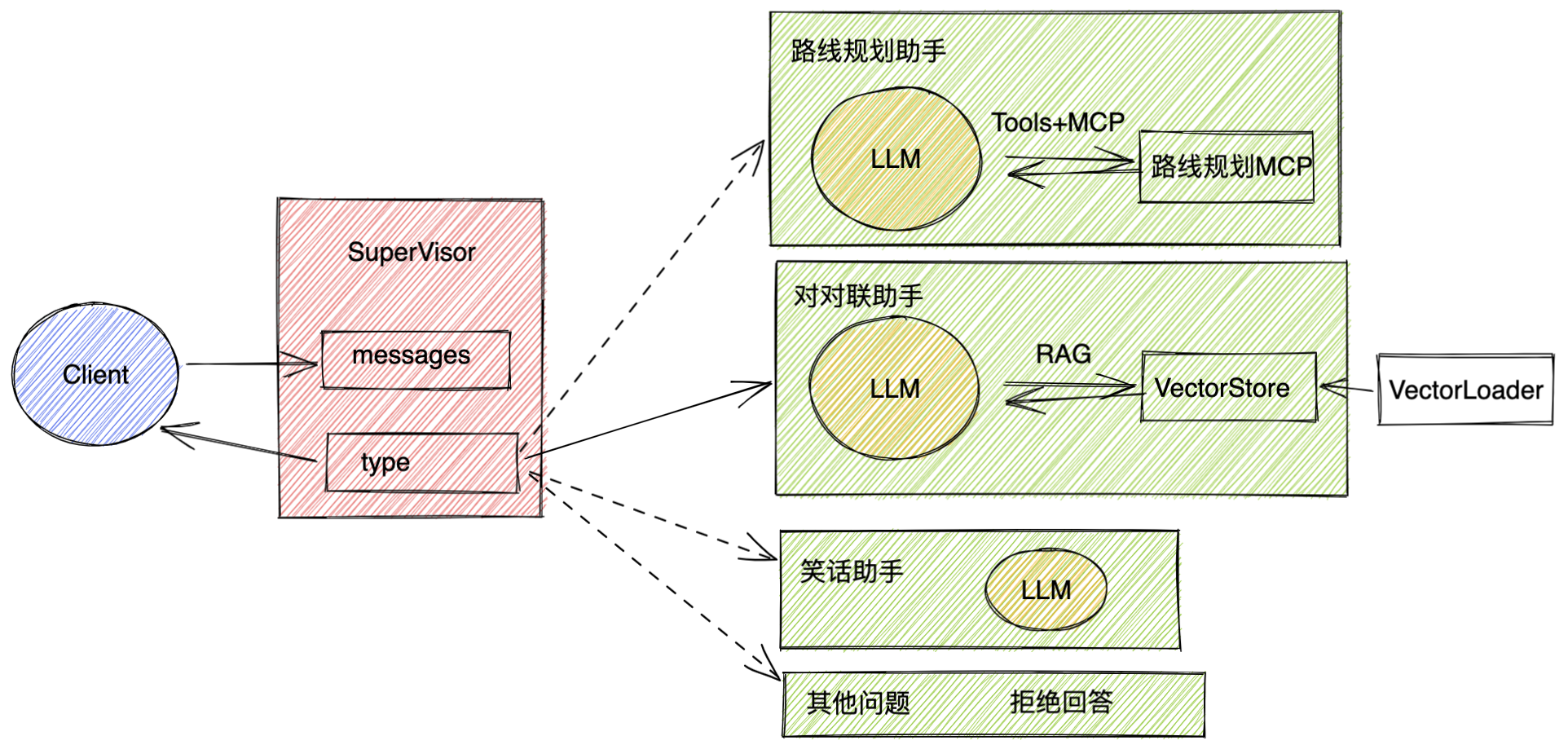
在实现时,为了能够更综合的演练这么⻓时间的学习效果,我们在对各个智能体的功能进⾏了⼀些设计,从⽽让这个⼩案例不再只是⼀个简单的Demo。
其他问题,只添加⼀个简单的响应结果。
笑话助⼿,直接与⼤模型交互获得⼀个结果。
对对联助⼿,从向量数据库中获取补充的资料,实现⼀个典型的RAG流程。
路线规划助⼿,则需要调度外部的MCP服务,获取补充信息。
这个案例,即作为LangGraph系列的总结演练,也作为⼀个典型的多智能体案例,强烈建议你,⾃⼰动⼿试试实现⼀个。在这个案例中,LangGraph更多的帮助我们来梳理各个智能体之间如何协调。⽽具体实现时,可以更多的借鉴LangChain的能⼒。还有,不要忘了,LangGraph还提供了很多开发过程中可以⽤到的⼯具,⽐如⾃定义流式输出、Time-travel时间重演等,都可以在这个案例中逐步尝试。
总结
从LangGraph的整个演练过程可以看到, LangGraph的核⼼是Graph。Graph其实是⼀个与⼤模型没有直接关联的,处理复杂任务的流程结构。LangGraph或者说整个LangChain系列,其实是将传统的软件构建经验与⼤语⾔模型的能⼒进⾏结合,从⽽进⼀步打造出强⼤的智能体,解决更多实际的复杂问题。这也进⼀步验证了,⼤语⾔模型未来的发展⽅向,⼀定是需要与传统应⽤相结合,这样才能更好的发挥⼤语⾔模型的价值。⽽这,或许是LangChain系列最核⼼的价值所在。
ps: 项目全部代码可在我的代码仓库获取🥰
AlexavierSeville/LangGraph-to-MultiAgent: 学习使用LangGraph构建多智能体